Originally published on the MyFitnessPal Blog
Think of a scaling problem, how does a system handle when an influx of traffic happens? Now imagine a bug, where essentially all messages were being held at the gate for a month. As more systems generate messages the queue scales. Up until September 15th, one of the queues grew to five hundred million messages.
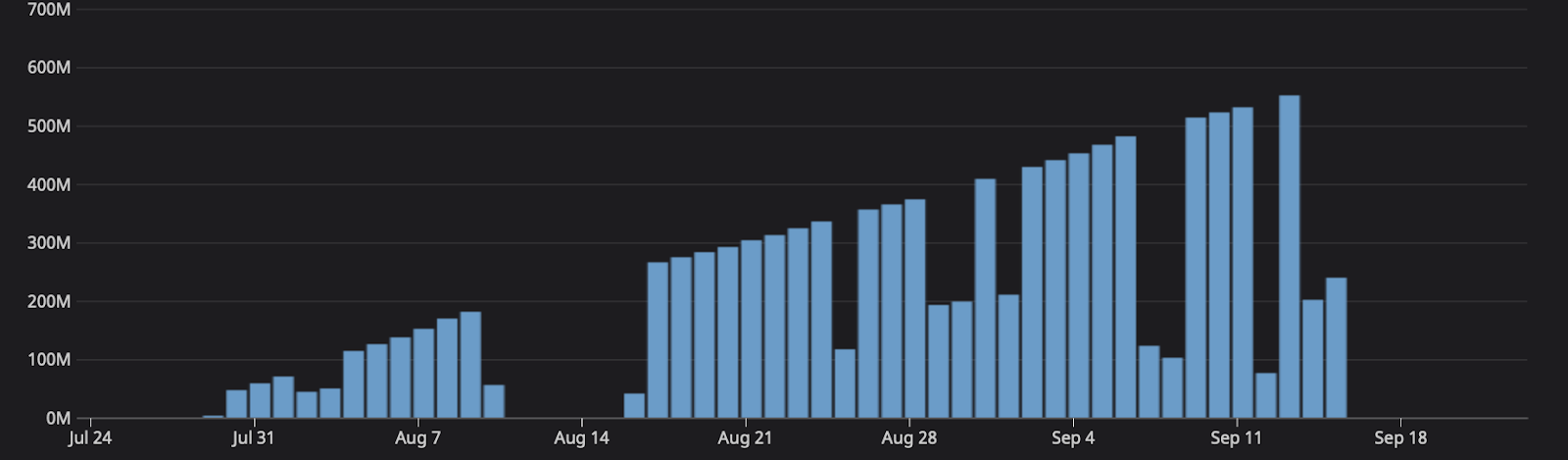
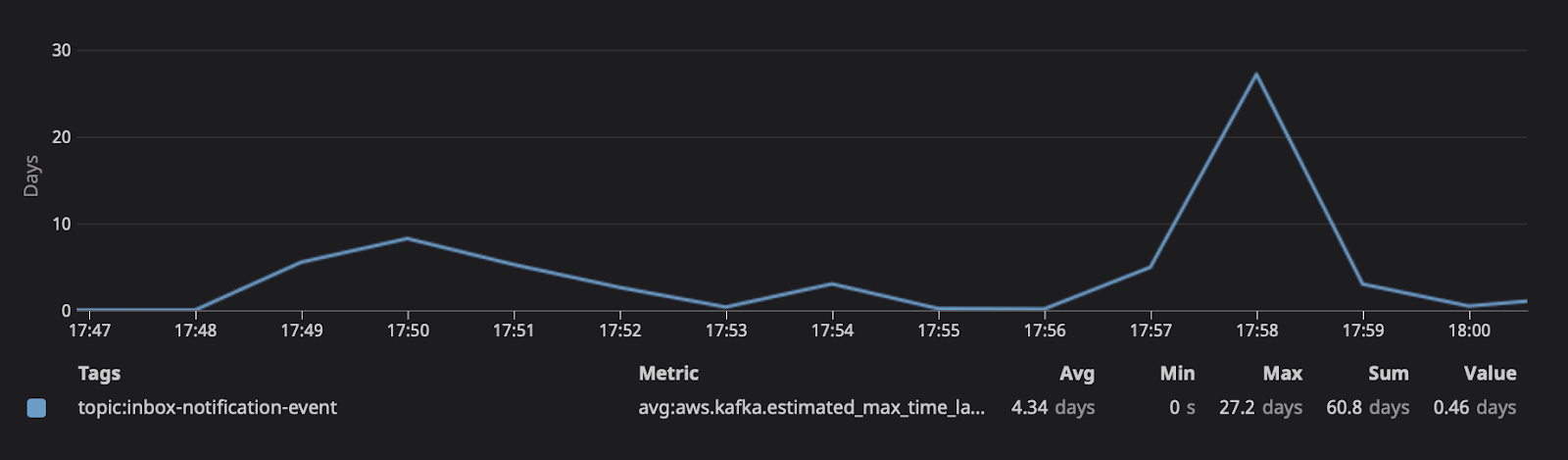
Remediating the bug resulted in removing the gates, subsequently causing processing time on the system to spike. On average, the system typically handles a few hundred messages, now we're asking it to process five hundred million at once. At 17:45, the consuming lag grew so large that at the current replica count, we can see the number of messages would take days to consume.
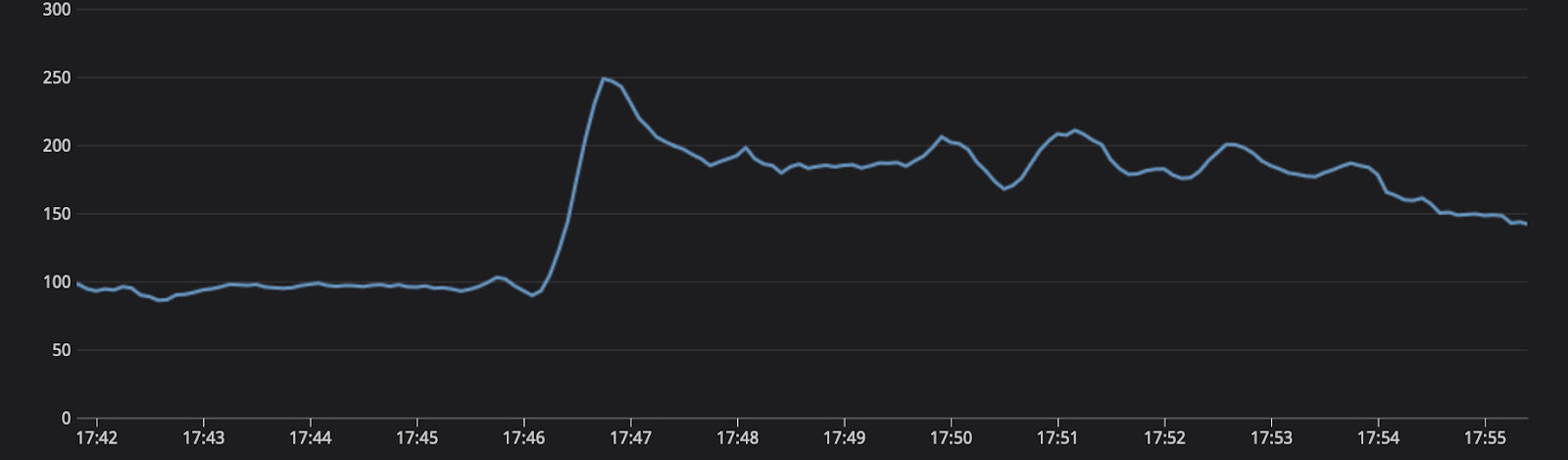
The engineering team has spent the last several months optimizing each of the backend services to be able to process load. One of the performance improvements put in was installing Horizontal Pod Autoscaling based on CPU load. Originally this effort aided in downsizing the number of replicas and providing some cost savings within our clusters. The scaling metric is one hundred percent average utilization. During the queue processing, we saw the load on the system grow to almost 250%.
At the point of pain, where the system is experiencing degradation, the auto scalers kick in. Swiftly doubling the fleet, allowing for more workers to process the queue, and then once complete, scaled back down to original capacity.
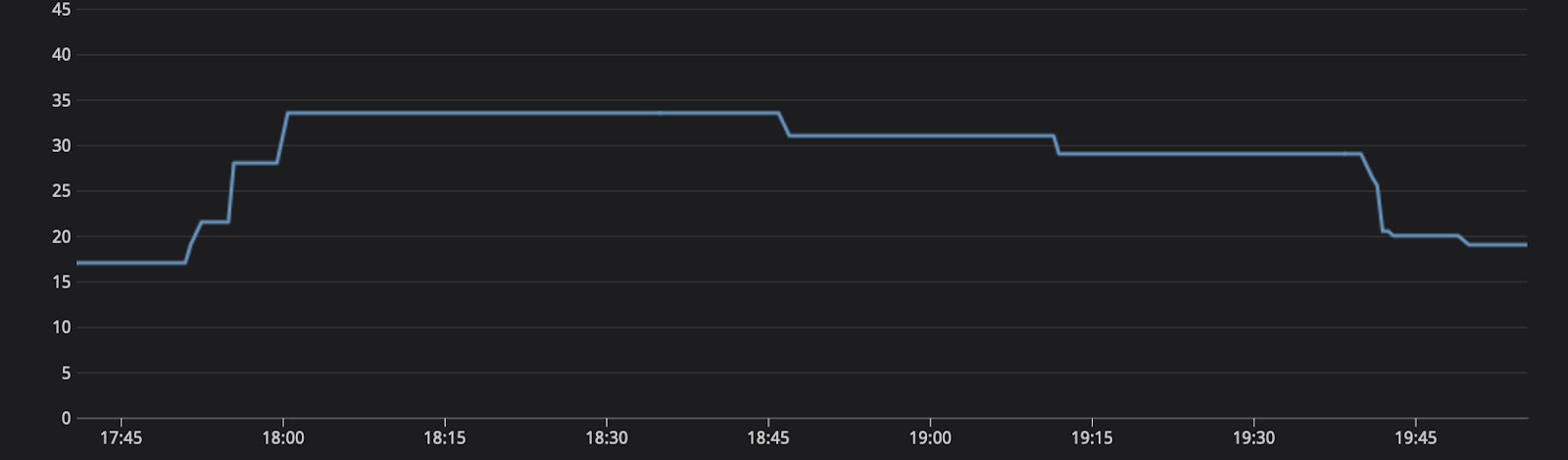
As a result of Kubernetes’ controllers managing the scale, the time to recovery was reduced from days to a few hours with no human interaction. In retrospect, troubleshooting what had happened wasn’t immediately apparent, so without HPAs it is possible the time to recovery would have been longer with previous processes. The scale-up also avoided any user-facing error spikes, since those messages also subsequently spiked traffic by greater than one hundred fifty percent of normal load, but were handled by the additional replicas.